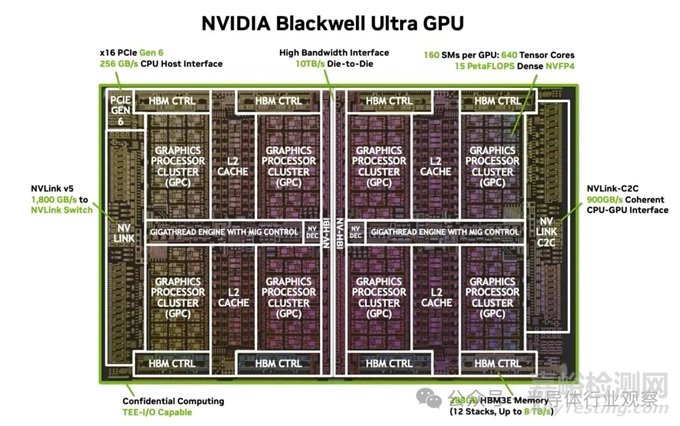
自GPU成為主流以來(lái)��,英偉達(dá)一直主導(dǎo)著GPU計(jì)算領(lǐng)域。該公司推出的Blackwell B200 GPU有望成為新一代的頂級(jí)計(jì)算GPU�。與前幾代產(chǎn)品不同,Blackwell無(wú)法像以往那樣依靠制程節(jié)點(diǎn)的改進(jìn)�。臺(tái)積電的4NP制程可能比上一代Hopper所使用的4N制程有所提升,但不太可能像之前的全節(jié)點(diǎn)縮小那樣帶來(lái)顯著的性能提升��。
因此��,Blackwell放棄了英偉達(dá)久經(jīng)考驗(yàn)的單芯片設(shè)計(jì)����,轉(zhuǎn)而采用兩個(gè)光罩大小的芯片。這兩個(gè)芯片在軟件層面被視為一個(gè)獨(dú)立的GPU�,這使得B200成為英偉達(dá)首款芯片級(jí)GPU。每個(gè)B200芯片物理上包含80個(gè)流式多處理器(SM)��,類似于CPU的核心。B200每個(gè)芯片支持74個(gè)SM�,因此整個(gè)GPU共有148個(gè)SM。時(shí)鐘頻率與 H100 的高功率 SXM5 版本相似��。
我在上表中列出了 H100 SXM5 的規(guī)格��,但除非另有說(shuō)明��,下文中的數(shù)據(jù)將來(lái)自 H100 PCIe 版本�。
緩存和內(nèi)存訪問(wèn)
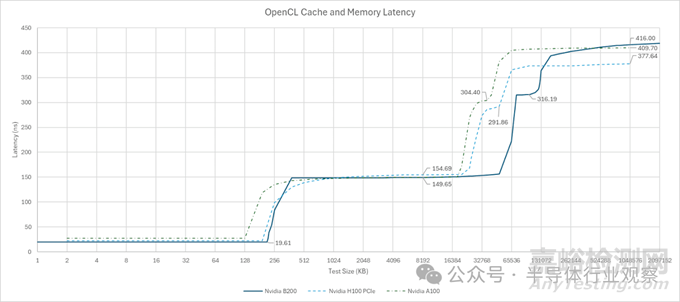
B200 的緩存層級(jí)結(jié)構(gòu)與 H100 和 A100 非常相似��。L1 緩存和共享內(nèi)存均從同一個(gè) SM 私有池中分配�。L1 緩存/共享內(nèi)存的容量與 H100 相同,仍為 256 KB�。L1 緩存/共享內(nèi)存的分配比例也未改變。共享內(nèi)存類似于 AMD 的本地?cái)?shù)據(jù)共享 (LDS) 或 Intel 的共享本地內(nèi)存 (SLM)��,它為一組線程提供軟件管理的片上本地存儲(chǔ)�。開發(fā)者可以通過(guò) Nvidia 的 CUDA API 來(lái)設(shè)置 L1 緩存的分配比例,例如:分配更大的 L1 緩存����、分配相等的 L1 緩存或分配更多的共享內(nèi)存。這些選項(xiàng)分別對(duì)應(yīng) 216 KB��、112 KB 和 16 KB 的 L1 緩存容量。
在其他 API 中����,共享內(nèi)存和 L1 緩存的分配完全取決于 Nvidia 的驅(qū)動(dòng)程序。OpenCL 獲得了最大的 216 KB 數(shù)據(jù)緩存分配��,而其內(nèi)核未使用共享內(nèi)存����,這相當(dāng)合理。Vulkan 獲得的 L1 緩存分配略小����,為 180 KB。經(jīng)測(cè)試��,OpenCL 中數(shù)組索引的 L1 緩存延遲僅為 19.6 納秒����,即 39 個(gè)時(shí)鐘周期。
與 A100 和 H100 一樣��,B200 也采用了分區(qū)式 L2 緩存��。然而��,其容量大幅提升,總?cè)萘窟_(dá)到 126 MB��。作為對(duì)比����,H100 的 L2 緩存容量為 50 MB,A100 為 40 MB�。直接連接到同一 L2 分區(qū)的延遲與前幾代產(chǎn)品類似,約為 150 納秒����。當(dāng)測(cè)試數(shù)據(jù)超出分區(qū)范圍時(shí)����,延遲會(huì)顯著增加。B200 的跨分區(qū)延遲比其前代產(chǎn)品略高����,但提升幅度不大。B200 上的 L2 分區(qū)幾乎可以肯定對(duì)應(yīng)于其兩個(gè)芯片��。如果是這樣����,跨芯片的延遲增加很小��,而且單個(gè) L2 分區(qū)的容量就超過(guò)了 H100 的整個(gè) L2 緩存容量��,因此可以忽略不計(jì)����。
從單線程的角度來(lái)看�,B200 的表現(xiàn)就像采用了三級(jí)緩存架構(gòu)。L2 緩存的分區(qū)特性可以通過(guò)將指針追蹤數(shù)組分段����,并讓不同的線程遍歷每個(gè)段來(lái)體現(xiàn)。奇怪的是�,我需要大量的線程才能訪問(wèn)大部分 126 MB 的容量而不產(chǎn)生跨分區(qū)性能損失?���;蛟S Nvidia 的調(diào)度器會(huì)先嘗試填充一個(gè)分區(qū)的 SM(流式多處理器),然后再訪問(wèn)另一個(gè)分區(qū)����。
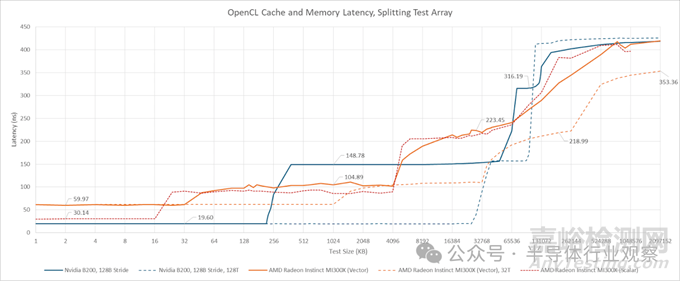
AMD 的 Radeon Instinct MI300X 采用真正的三級(jí)緩存架構(gòu),與 B200 系列顯卡不相上下����。Nvidia 的 L1 緩存容量更大��、速度更快����。AMD 的 L2 緩存犧牲了部分容量����,換取了比 Nvidia 更低的延遲。最后��,AMD 的 256 MB 末級(jí)緩存實(shí)現(xiàn)了低延遲和高容量的完美結(jié)合��,其延遲甚至低于 Nvidia 的“遠(yuǎn)端”L2 分區(qū)��。
一個(gè)有趣的現(xiàn)象是�,當(dāng)多個(gè)線程訪問(wèn)分段指針追蹤數(shù)組時(shí),MI300X 和 B200 在末級(jí)緩存 (TLB) 上的延遲都更加均勻����。然而��,造成延遲增加的原因卻不盡相同�。AMD 平臺(tái)上超過(guò) 64MB 后的延遲增加似乎是由 TLB 未命中引起的,因?yàn)槭褂?4KB 步長(zhǎng)進(jìn)行測(cè)試時(shí)����,在同一位置也出現(xiàn)了延遲增加����。啟動(dòng)更多線程會(huì)增加 TLB 實(shí)例的參與度����,從而減輕地址轉(zhuǎn)換的懲罰。消除 TLB 未命中懲罰也降低了 MI300X 的 VRAM 延遲�。而對(duì)于 B200 來(lái)說(shuō),拆分?jǐn)?shù)組并沒(méi)有降低 VRAM 延遲�,這表明 TLB 未命中要么在單線程情況下并非主要因素,要么增加線程數(shù)并沒(méi)有減少 TLB 未命中�。因此,B200 的 VRAM 延遲似乎高于 MI300X 以及更早的 H100 和 A100����。與 L2 跨分區(qū)懲罰一樣,與 H100/A100 相比����,延遲回歸的程度并不嚴(yán)重,這表明英偉達(dá)的多芯片設(shè)計(jì)運(yùn)行良好�。
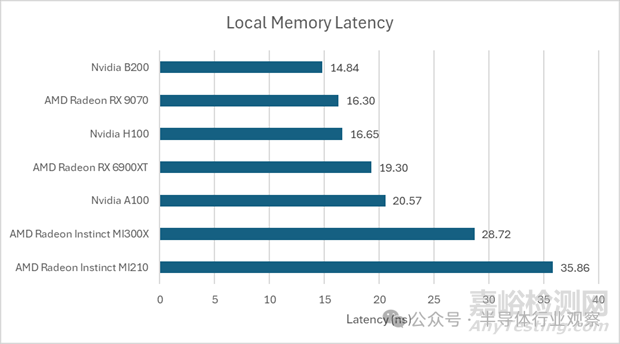
OpenCL 的本地內(nèi)存空間由英偉達(dá)的共享內(nèi)存 (Shared Memory)、AMD 的 LDS 或英特爾的 SLM 提供支持��。使用陣列訪問(wèn)測(cè)試本地內(nèi)存延遲表明,B200 延續(xù)了其在共享內(nèi)存延遲方面的出色表現(xiàn)��。其訪問(wèn)速度比我迄今為止測(cè)試過(guò)的任何 AMD GPU 都要快��,包括 RDNA 系列的高頻型號(hào)��。AMD 基于 CDNA 架構(gòu)的 GPU 的本地內(nèi)存延遲則要高得多�。
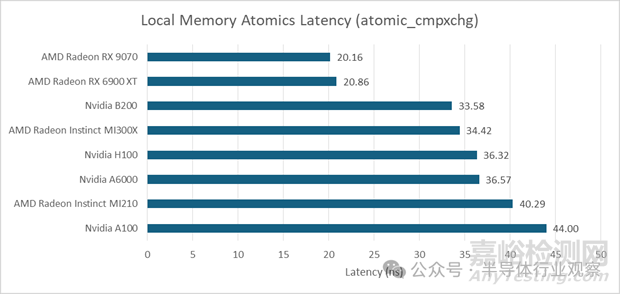
原子操作可用于在同一工作組內(nèi)的線程之間交換數(shù)據(jù)。在Nvidia平臺(tái)上�,這意味著運(yùn)行在同一SM上的線程之間交換數(shù)據(jù)。使用atomic_cmpxchg在線程間快速傳遞數(shù)據(jù)�,其延遲與AMD的MI300X相當(dāng)。與指針追蹤延遲一樣����,B200相比前幾代產(chǎn)品僅有小幅改進(jìn)。與大型計(jì)算GPU相比�,AMD的RDNA系列在此項(xiàng)測(cè)試中表現(xiàn)出色。
現(xiàn)代GPU使用專用的原子ALU來(lái)處理原子加法和遞增等操作����。使用atomic_add進(jìn)行測(cè)試��,B200的每個(gè)SM每個(gè)周期可以執(zhí)行32次操作����。這個(gè)測(cè)試是在MI300X測(cè)試結(jié)束后編寫的��,所以我只有MI300A的數(shù)據(jù)�。與GCN架構(gòu)類似�,AMD的CDNA3計(jì)算單元每個(gè)周期可以執(zhí)行16次原子加法。這使得B200盡管核心數(shù)量較少����,卻依然能夠勝出。
帶寬測(cè)量
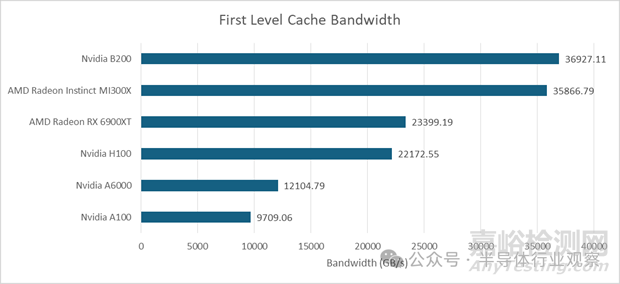
更高的SM單元數(shù)量使B200的L1緩存帶寬比其前代產(chǎn)品有了顯著優(yōu)勢(shì)��。在OpenCL測(cè)試中�,它的性能也趕上了AMD的MI300X。而像RX 6900XT這樣較老����、尺寸較小的消費(fèi)級(jí)GPU則被遠(yuǎn)遠(yuǎn)甩在了后面。
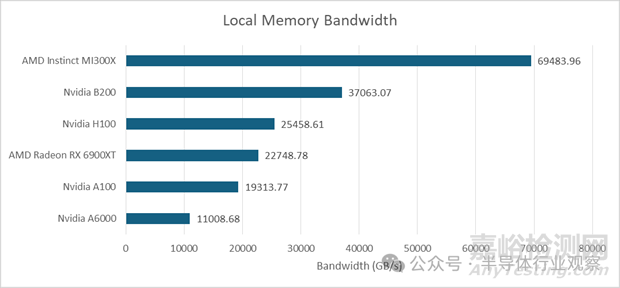
在B200平臺(tái)上����,本地內(nèi)存和L1緩存的帶寬相同,因?yàn)樗鼈兌蓟谕粔K存儲(chǔ)介質(zhì)��。這使得AMD的MI300X在帶寬方面擁有巨大的優(yōu)勢(shì)。本地內(nèi)存更難充分利用����,因?yàn)殚_發(fā)者必須顯式地管理數(shù)據(jù)移動(dòng),而緩存則能自動(dòng)利用局部性�。但即便如此,MI300X在這一領(lǐng)域依然保持領(lǐng)先地位�。
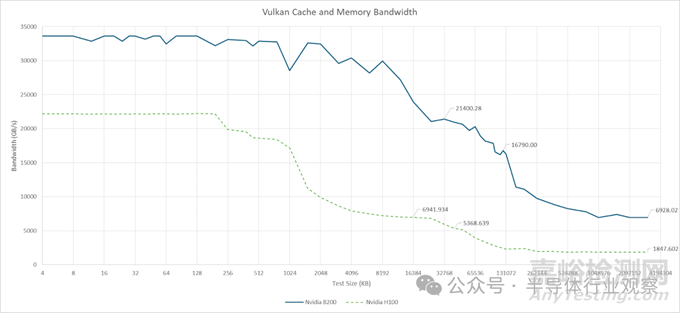
Nemez 基于 Vulkan 的基準(zhǔn)測(cè)試可以大致反映 B200 的 L2 帶寬情況。本地 L2 分區(qū)內(nèi)較小的數(shù)據(jù)量可以達(dá)到 21 TB/s 的帶寬�。當(dāng)數(shù)據(jù)開始在兩個(gè)分區(qū)之間傳輸時(shí),帶寬會(huì)下降到 16.8 TB/s��。AMD 的 MI300X 不支持圖形 API����,也無(wú)法運(yùn)行 Vulkan 計(jì)算。不過(guò)��,AMD 指出其 256 MB 的 Infinity Cache 可以提供 14.7 TB/s 的帶寬����。MI300X 不需要從 Infinity Cache 獲得如此高的帶寬,因?yàn)槠淝懊娴?4 MB L2 實(shí)例應(yīng)該可以吸收大部分 L1 緩存未命中流量��。
與上一代 H100 相比����,B200 在緩存層次結(jié)構(gòu)的各個(gè)層級(jí)都擁有顯著的帶寬優(yōu)勢(shì)。得益于 HBM3E��,B200 的顯存帶寬也優(yōu)于 MI300X�。雖然 MI300X 也配備了八個(gè) HBM 堆棧,但它使用的是較老的 HBM3����,最高帶寬僅為 5.3 TB/s。
全局內(nèi)存原子
(Global Memory Atomics)
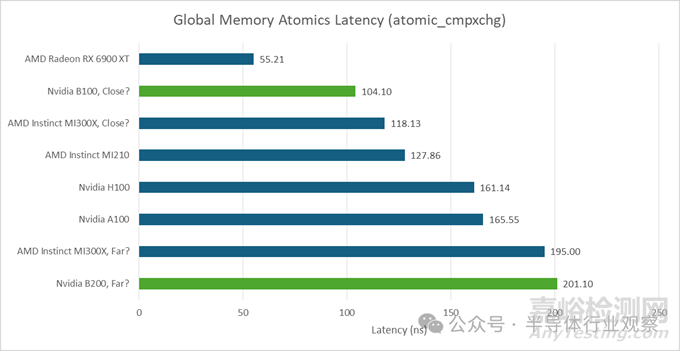
AMD 的 MI300X 在使用 atomic_cmpxchg 在線程間切換數(shù)值時(shí)表現(xiàn)出不同的延遲�。其復(fù)雜的多芯片結(jié)構(gòu)可能是造成這種現(xiàn)象的原因。B200 也存在同樣的問(wèn)題�。在這里,我啟動(dòng)了與 GPU 核心(SM 或 CU)數(shù)量相同的單線程工作組�,并選擇不同的線程對(duì)進(jìn)行測(cè)試。我使用的訪問(wèn)模式類似于 CPU 端核心間延遲測(cè)試��,但無(wú)法控制每個(gè)線程的放置位置��。因此����,這并非一個(gè)標(biāo)準(zhǔn)的 CPU 端核心間延遲測(cè)試,且不同運(yùn)行的結(jié)果并不一致�。但這足以展示延遲的變化,并表明 B200 具有雙峰延遲分布。
在理想情況下����,延遲為 90-100 納秒,這很可能是因?yàn)榫€程位于同一個(gè) L2 分區(qū)上��。在較差的情況下�,延遲則在 190-220 納秒之間,這很可能是因?yàn)橥ㄐ趴缭搅?L2 分區(qū)邊界����。AMD MI300X 的測(cè)試結(jié)果在 116 納秒到 202 納秒之間。B200 在理想情況下的性能略優(yōu)于 AMD�,但在較差情況下的性能則略遜一籌。
與RX 6900XT等高頻消費(fèi)級(jí)GPU相比�,數(shù)據(jù)中心GPU的線程間延遲通常更高。即使在最佳情況下�,在擁有數(shù)百個(gè)SM或CU的GPU之間交換數(shù)據(jù)也是一項(xiàng)挑戰(zhàn)。
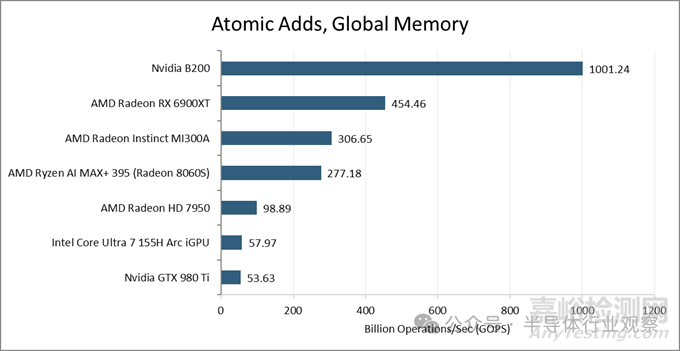
全局內(nèi)存上的原子操作通常由GPU共享緩存級(jí)別的專用ALU處理��。Nvidia的B200芯片每個(gè)周期可以支持GPU上近512次此類操作��。AMD的MI300A芯片在這項(xiàng)測(cè)試中表現(xiàn)不佳��,吞吐量甚至低于面向消費(fèi)者的RX 6900XT����。
計(jì)算吞吐量
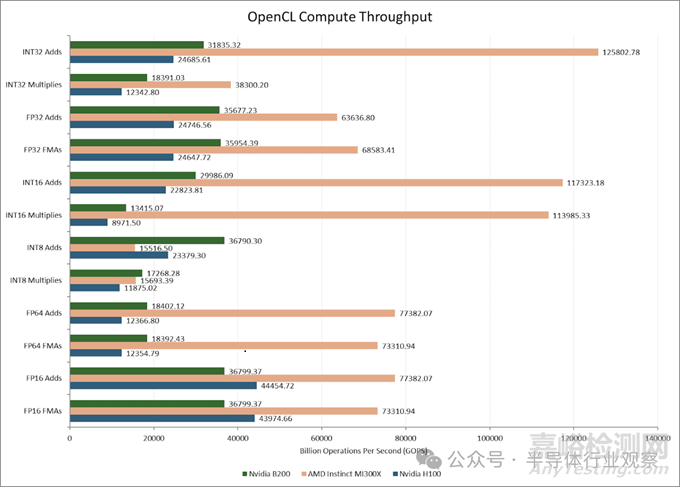
SM 數(shù)量的增加使得 B200 在大多數(shù)向量運(yùn)算中擁有比 H100 更高的計(jì)算吞吐量�。然而����,F(xiàn)P16 運(yùn)算是個(gè)例外����。Nvidia 的舊款 GPU 可以以 FP32 兩倍的速度執(zhí)行 FP16 運(yùn)算,而 B200 則不能�。
AMD 的 MI300X 也能進(jìn)行雙倍速率的 FP16 計(jì)算。英偉達(dá)可能決定將 FP16 計(jì)算的重點(diǎn)放在 Tensor Core(矩陣乘法單元)上�。總的來(lái)說(shuō)��,MI300X 的強(qiáng)大運(yùn)算能力在大多數(shù)向量運(yùn)算方面都遠(yuǎn)超 H100 和 B200����。盡管采用了較舊的制程工藝,AMD 激進(jìn)的芯片組架構(gòu)仍然具有優(yōu)勢(shì)����。
張量?jī)?nèi)存
B200 的目標(biāo)應(yīng)用是人工智能,因此��,如果不提及它的機(jī)器學(xué)習(xí)優(yōu)化,討論就不完整����。英偉達(dá)早在圖靈/伏特架構(gòu)時(shí)代就開始使用張量核心(Tensor Core),也就是專用的矩陣乘法單元��。GPU 提供了一種 SIMT 編程模型��,開發(fā)者可以將每個(gè)通道視為一個(gè)獨(dú)立的線程��,至少?gòu)恼_性的角度來(lái)看是如此��。張量核心打破了 SIMT 的抽象�,要求矩陣在一個(gè)波(或向量)上采用特定的布局。Blackwell 的第五代張量核心更進(jìn)一步����,允許矩陣在一個(gè)工作組(CTA)中跨越多個(gè)波。
Blackwell 還引入了張量?jī)?nèi)存(Tensor Memory����,簡(jiǎn)稱 TMEM)。TMEM 類似于專用于張量核心(Tensor Core)的寄存器文件��。開發(fā)人員可以將矩陣數(shù)據(jù)存儲(chǔ)在 TMEM 中�,Blackwell 的工作組級(jí)矩陣乘法指令使用 TMEM 而非寄存器文件�。TMEM 的組織結(jié)構(gòu)為 512 列 x 128 行�,每個(gè)單元格為 32 位。每個(gè)波形只能訪問(wèn) 32 行 TMEM 數(shù)據(jù)��,具體行數(shù)由其波形索引決定�。這意味著每個(gè) SM 子分區(qū)都有一個(gè) 512 列 x 32 行的 TMEM 分區(qū)。“張量核心收集器緩沖區(qū)”(TensorCore Collector Buffer)可以利用矩陣數(shù)據(jù)重用����,充當(dāng) TMEM 的寄存器重用緩存�。
因此,TMEM 的工作方式類似于 AMD CDNA 架構(gòu)上的累加器寄存器文件 (Acc VGPR)��。CDNA 的 MFMA 矩陣指令同樣操作 Acc VGPR 中的數(shù)據(jù)��,但 MFMA 也可以從常規(guī) VGPR 中獲取源矩陣����。在 Blackwell 架構(gòu)上,只有較早的波形級(jí)矩陣乘法指令才接受常規(guī)寄存器輸入����。TMEM 和 CDNA 的 Acc VGPR 容量均為 64 KB,因此兩種架構(gòu)的每個(gè)執(zhí)行單元分區(qū)都擁有 64+64 KB 的寄存器文件�。常規(guī)向量執(zhí)行單元無(wú)法從 Nvidia 的 TMEM 或 AMD 的 Acc VGPR 中獲取輸入��。
盡管 Blackwell 的 TMEM 和 CDNA 的 Acc VGPR 在總體目標(biāo)上相似�,但 TMEM 對(duì)分離式寄存器文件理念的實(shí)現(xiàn)更加完善和成熟�。CDNA 必須為每個(gè) wave 分配相同數(shù)量的 Acc 和常規(guī) VGPR。這樣做可能簡(jiǎn)化了簿記��,但卻造成了一種不靈活的安排����,即混合使用矩陣波和非矩陣波會(huì)導(dǎo)致寄存器文件容量的低效利用。相比之下����,TMEM 使用了一種動(dòng)態(tài)分配方案,其原理類似于 AMD RDNA4 上的動(dòng)態(tài) VGPR 分配����。每個(gè) wave 開始時(shí)都沒(méi)有分配 TMEM,并且可以分配 32 到 512 列(以 2 的冪次方為單位)����。所有行同時(shí)分配,并且 wave 必須在退出前顯式釋放已分配的 TMEM�。TMEM 還可以從共享內(nèi)存或常規(guī)寄存器文件加載,而 CDNA 的 Acc VGPR 只能通過(guò)常規(guī) VGPR 加載����。最后����,TMEM 可以在加載數(shù)據(jù)時(shí)選擇性地將 4 位或 6 位數(shù)據(jù)類型“解壓縮”為 8 位����。

與之前的英偉達(dá)架構(gòu)相比,引入 TMEM 有助于降低常規(guī)寄存器文件的容量和帶寬壓力��。引入 TMEM 可能比擴(kuò)展常規(guī)寄存器文件更容易��。Blackwell 的 CTA 級(jí)矩陣指令每個(gè)周期�、每個(gè)分區(qū)可以支持 1024 次 16 位 MAC 操作�。由于矩陣輸入始終來(lái)自共享內(nèi)存,TMEM 每個(gè)周期只需讀取一行并將其累加到另一行����。而常規(guī)向量寄存器對(duì)于 FMA 指令則需要每個(gè)周期進(jìn)行三次讀取和一次寫入。此外��,TMEM 無(wú)需連接到向量單元��。所有這些特性使得 Blackwell 能夠像擁有更大的寄存器文件一樣運(yùn)行����,從而簡(jiǎn)化硬件�。自 2012 年 Kepler 架構(gòu)以來(lái)�,英偉達(dá)一直使用 64 KB 的寄存器文件,因此增加寄存器文件容量似乎勢(shì)在必行����。TMEM 在某種程度上實(shí)現(xiàn)了這一點(diǎn)。
AMD方面����,CDNA2放棄了專用的Acc VGPR,并將所有VGPR合并到一個(gè)統(tǒng)一的128KB寄存器池中�。采用更大的統(tǒng)一寄存器池可以使更廣泛的應(yīng)用程序受益,但代價(jià)是無(wú)法簡(jiǎn)化某些硬件�。
一些簡(jiǎn)單的基準(zhǔn)測(cè)試
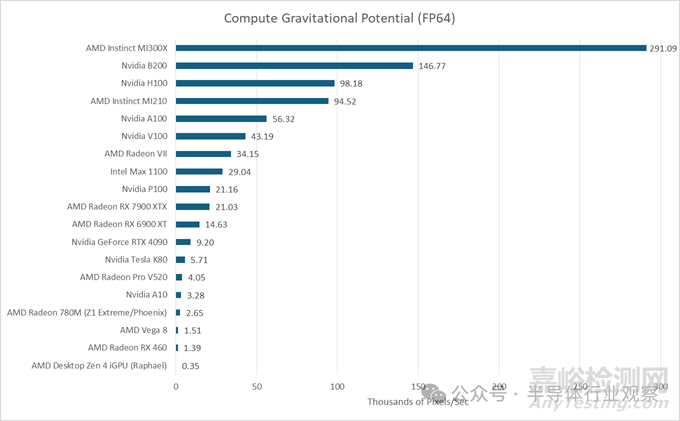
數(shù)據(jù)中心級(jí)GPU歷來(lái)?yè)碛袕?qiáng)大的FP64性能,B200也不例外�。其基本FP64運(yùn)算速度僅為FP32的一半,遠(yuǎn)超消費(fèi)級(jí)GPU��。在我們自行編寫的基準(zhǔn)測(cè)試中����,B200的表現(xiàn)依然優(yōu)于消費(fèi)級(jí)GPU和H100。然而,即便MI300X是一款即將停產(chǎn)的GPU�,其龐大的體積依然顯露無(wú)疑。
在上述工作負(fù)載中�,我使用一個(gè) 2360x2250 的 FITS 文件(包含列密度值)并輸出相同尺寸的引力勢(shì)值。因此��,數(shù)據(jù)量為 85 MB����。即使沒(méi)有性能計(jì)數(shù)器數(shù)據(jù),也可以合理地假設(shè)它能夠放入 MI300X 和 B200 的末級(jí)緩存中��。
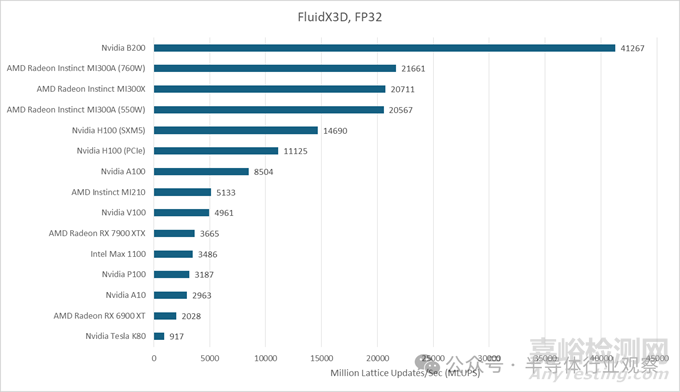
FluidX3D 的情況則有所不同��。它的基準(zhǔn)測(cè)試采用 256x256x256 的單元配置�,F(xiàn)P32 模式下每個(gè)單元占用 93 字節(jié),因此需要 1.5 GB 的內(nèi)存��。根據(jù)在 Strix Halo 顯卡上使用性能計(jì)數(shù)器進(jìn)行的測(cè)試�,它的訪問(wèn)模式對(duì)緩存并不友好��。FluidX3D 充分發(fā)揮了 B200 的顯存帶寬優(yōu)勢(shì)��,目前 B200 的性能已經(jīng)超越了 MI300X�。
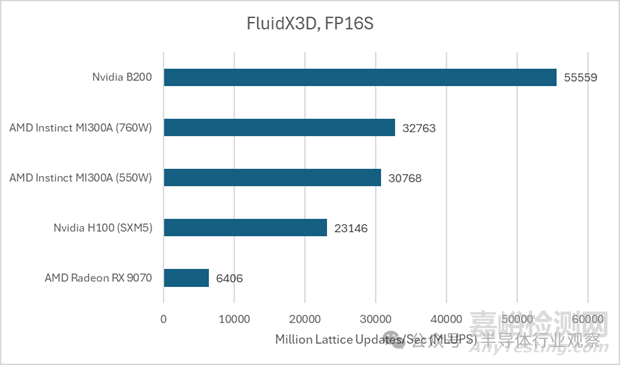
FluidX3D 還可以使用 16 位浮點(diǎn)格式進(jìn)行存儲(chǔ),從而降低內(nèi)存容量和帶寬需求。計(jì)算仍然使用 FP32��,格式轉(zhuǎn)換需要額外的計(jì)算資源��,因此 FP16 格式可以帶來(lái)更高的計(jì)算帶寬比����。這通常會(huì)提升性能,因?yàn)?FluidX3D 的性能很大程度上受限于帶寬��。當(dāng)使用 IEEE FP16 進(jìn)行存儲(chǔ)時(shí)����,AMD 的 MI300A 略有進(jìn)步,但仍然遠(yuǎn)勝于 B200�。
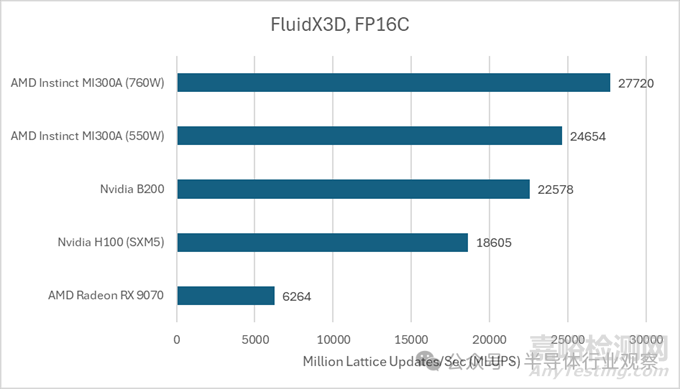
另一種 FP16C 格式降低了使用 16 位存儲(chǔ)格式帶來(lái)的精度損失。它是一種無(wú)需硬件支持的自定義浮點(diǎn)格式����,這進(jìn)一步提高了計(jì)算帶寬比。
計(jì)算能力再次成為焦點(diǎn)����,AMD 的 MI300A 脫穎而出。B200 的表現(xiàn)也不錯(cuò)��,但它無(wú)法與 AMD 大型芯片 GPU 所提供的強(qiáng)大計(jì)算吞吐量相媲美
Teething Issues
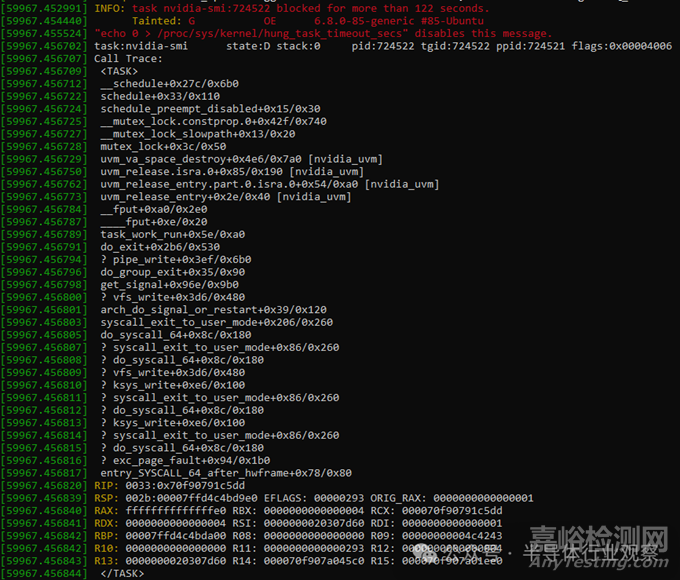
在數(shù)周的測(cè)試中,我們遇到了三次 GPU 掛起問(wèn)題��。問(wèn)題表現(xiàn)為 GPU 進(jìn)程卡死��。隨后����,任何嘗試使用系統(tǒng)八個(gè) GPU 中任何一個(gè)的進(jìn)程都會(huì)掛起。即使使用 SIGKILL 信號(hào)也無(wú)法終止任何掛起的進(jìn)程�。將 GDB 附加到其中一個(gè)進(jìn)程也會(huì)導(dǎo)致 GDB 凍結(jié)。系統(tǒng)對(duì)僅使用 CPU 的應(yīng)用程序保持響應(yīng)��,但只有重啟系統(tǒng)才能恢復(fù) GPU 功能����。nvidia-smi 進(jìn)程也會(huì)掛起。內(nèi)核消息顯示�,Nvidia 統(tǒng)一內(nèi)存內(nèi)核模塊(nvidia_uvm)在禁用搶占的情況下獲取了鎖。
堆棧跟蹤信息表明����,Nvidia 可能正在嘗試釋放已分配的虛擬內(nèi)存,或許是在 GPU 上����。獲取鎖是合理的,因?yàn)?Nvidia 可能不希望其他線程在頁(yè)面空閑列表被修改時(shí)訪問(wèn)它����。至于為什么它始終無(wú)法離開臨界區(qū),原因尚不清楚��?���;蛟S它向 GPU 發(fā)出了請(qǐng)求但從未收到響應(yīng)。又或許這純粹是主機(jī)端的一個(gè)軟件死鎖 bug����。
# nvidia-smi -r
The following GPUs could not be reset:
GPU 00000000:03:00.0: In use by another client
GPU 00000000:04:00.0: In use by another client
GPU 00000000:05:00.0: In use by another client
GPU 00000000:06:00.0: In use by another client
GPU 00000000:07:00.0: In use by another client
GPU 00000000:08:00.0: In use by another client
GPU 00000000:09:00.0: In use by another client
GPU 00000000:0A:00.0: In use by another client
出現(xiàn)這種系統(tǒng)卡死的情況并不令人意外。硬件加速增加了系統(tǒng)的復(fù)雜性����,也就意味著更多的故障點(diǎn)。但現(xiàn)代硬件架構(gòu)已經(jīng)發(fā)展到無(wú)需重啟即可處理GPU問(wèn)題�。例如,Windows的超時(shí)檢測(cè)與恢復(fù)(TDR)機(jī)制可以請(qǐng)求驅(qū)動(dòng)程序重置卡死的GPU����。nvidia-smi確實(shí)提供了重置選項(xiàng)。但令人沮喪的是����,如果GPU正在使用中����,該選項(xiàng)就無(wú)法生效�。這完全違背了提供重置選項(xiàng)的初衷。我希望Nvidia能夠隨著時(shí)間的推移解決這些問(wèn)題�,尤其是在根本原因完全在于軟件或固件的情況下。但在如此短的時(shí)間內(nèi)多次遇到此類問(wèn)題并非好兆頭��,如果Nvidia能夠提供無(wú)需重啟系統(tǒng)即可解決此類問(wèn)題的方法��,那就更好了����。
結(jié)語(yǔ)
英偉達(dá)在芯片組升級(jí)方面并未做出重大性能妥協(xié)。B200 是 H100 和 A100 的直接繼任者�,軟件無(wú)需考慮多芯片架構(gòu)。與 AMD 的 MI300X(12 芯片怪獸)相比�,英偉達(dá)的多芯片策略顯得較為保守。盡管 MI300X 已是即將停產(chǎn)的產(chǎn)品�,但它仍然保留了一些令人驚喜的優(yōu)勢(shì),優(yōu)于英偉達(dá)最新的 GPU�。AMD 即將推出的數(shù)據(jù)中心 GPU 很可能也會(huì)保持這些優(yōu)勢(shì),同時(shí)在 B200 已經(jīng)領(lǐng)先一些的領(lǐng)域迎頭趕上�。例如�,MI350X 將把顯存帶寬提升至 8 TB/s��。
但英偉達(dá)的保守策略是可以理解的��。他們的優(yōu)勢(shì)不在于打造市面上最強(qiáng)大�、性能最卓越的GPU�,而在于其CUDA軟件生態(tài)系統(tǒng)。GPU計(jì)算代碼通常首先針對(duì)英偉達(dá)GPU編寫��,而對(duì)非英偉達(dá)GPU的考慮則往往是次要的����,甚至根本不會(huì)考慮。硬件如果沒(méi)有相應(yīng)的軟件運(yùn)行�,就毫無(wú)用處,而快速移植也無(wú)法獲得同等程度的優(yōu)化����。英偉達(dá)無(wú)需在所有方面都與MI300X或其后續(xù)產(chǎn)品匹敵,他們只需要足夠優(yōu)秀����,足以阻止競(jìng)爭(zhēng)對(duì)手填補(bǔ)CUDA的“護(hù)城河”即可。試圖打造一款能夠與MI300X匹敵的“怪物”風(fēng)險(xiǎn)極大��,而英偉達(dá)在占據(jù)市場(chǎng)主導(dǎo)地位的情況下,完全有理由規(guī)避風(fēng)險(xiǎn)��。
盡管如此��,英偉達(dá)的策略也給AMD留下了機(jī)會(huì)��。AMD如果敢于冒險(xiǎn)�、追求卓越,必將獲益匪淺����。像MI300X這樣的GPU堪稱硬件工程的杰作,充分展現(xiàn)了AMD實(shí)現(xiàn)高難度設(shè)計(jì)目標(biāo)的能力����。英偉達(dá)保守的硬件策略和強(qiáng)大的軟件實(shí)力能否使其繼續(xù)保持領(lǐng)先地位,值得我們拭目以待��。
參考鏈接
https://chipsandcheese.com/p/nvidias-b200-keeping-the-cuda-juggernaut